
Scanning documents for personal data
The business idea of identification of sensitive data needs no introduction. In my opinion, it is one of the most popular use-cases for Machine Learning. In this simple application (github.com/konvica/read-presonal-data), I leverage several libraries (spacy, presidio, pymupdf, pytesseract, OpenCV, streamlit) to process PDF or image documents and extract all personal and sensitive data like photos of a face or personal information.
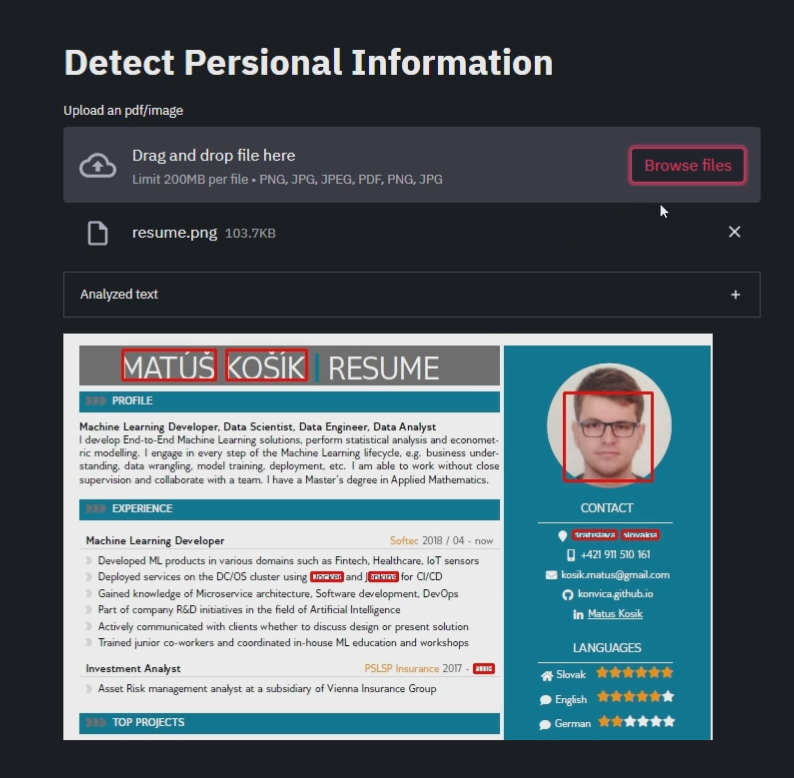
PDF files are extracted with the pymupdf library. Each page of pdf is processed sequentially. Named Entity Recognition NER using spacy and presidio is applied on the text of the whole page. Only English is supported. Supported entities are described here. Detected entities and personal information are then visualized in a streamlit app.
Image files and any images extracted from PDF files are scanned for faces using OpenCV and its haarcascade_frontalface detector. Based on pytesseract, presidio OCR with entity recognition is applied on text in image. Found faces and personal text data are highlighted with bounding boxes in the streamlit app.
To set it up you need anaconda or miniconda and to follow instructions in the repository github.com/konvica/read-presonal-data.